Environmental sound extraction using onomatopoeic words
Author: Yuki Okamoto1, Shota Horiguchi2, Masaaki Yamamoto2, Keisuke Imoto3, Yohei Kawaguchi2
Affiliation: 1 Ritsumeikan University, 2 Hitachi, Ltd., 3 Doshisha University
This is a demonstration of environmental sound extraction using an onomatopoeic word. We conducted environmental sound extraction using one proposed method and two comparison methods as follows:
- Superclass-conditioned method (Baseline) This method is uses a superclass sound event classes as a condition.
- Subclass-conditioned method (Baseline) This method is uses a subclass sound event classes as a condition.
- Onomatopoeia-conditioned method (Proposed) This method is uses an onomatopoeic word as a condition.
As sounds of the dataset, we used RWCP-SSD (Real World Computing Partnership-sound Scene Database) [1].
Some sound events in RWCP-SSD are labeled in the “event entry + ID” format, e.g., whistle1 and whistle2.
We created hierarchical sound-event classes by grouping labels with the same event entry, e.g., whistle.
We first selected 44 sound events from RWCP-SSD, which we call subclasses, and grouped them into 16 superclasses.
For the onomatopoeic words corresponding to each sound sample, we used the dataset in RWCP-SSD-Onomatopoeia [2].
We conducted the following three evaluation datasets using the selected sound events:
- (I) Inter-superclass dataset (samples of extracted sounds) Each mixture sound in this dataset is composed of a target sound and interference sounds, the superclass of each is different from that of the target sound.
- (II) Intra-superclass dataset (samples of extracted sounds) Each mixture sound in this dataset is composed of a target sound and interference sounds, the superclass of each is the same as that of the target sound, but the subclass is different.
- (III) Intra-subclass dataset (samples of extracted sounds) Each mixture sound in this dataset is composed of a target sound and interference sounds, the subclass of each is the same as that of the target sound, but the onomatopoeic word is different.
(I) Examples of environmental sound extraction using inter-superclass dataset
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
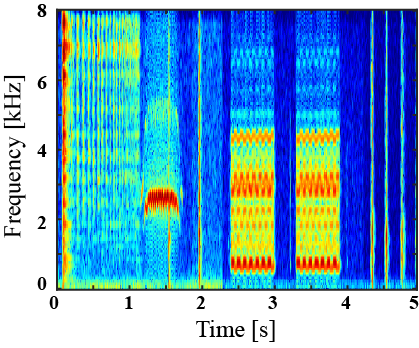
|
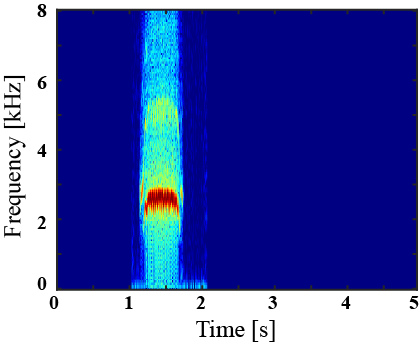
|
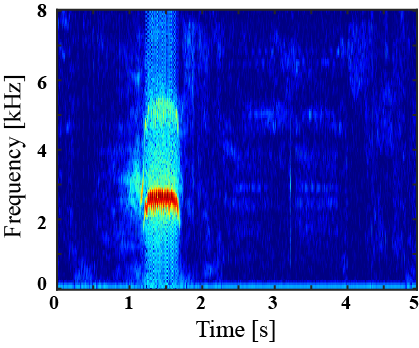
|
|
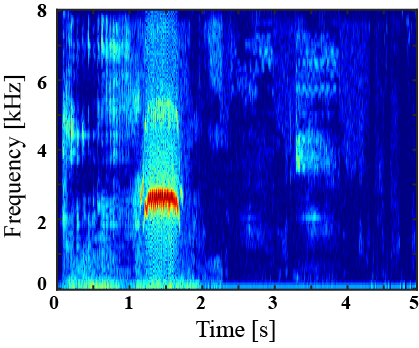
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
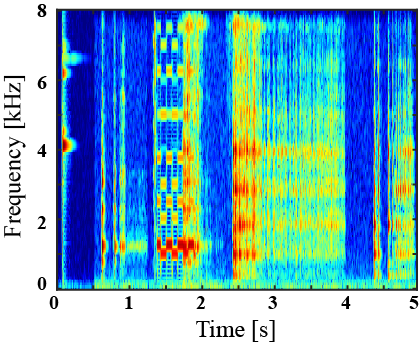
|
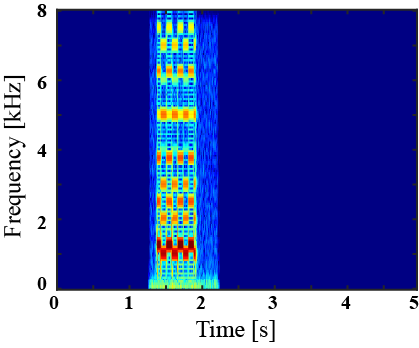
|
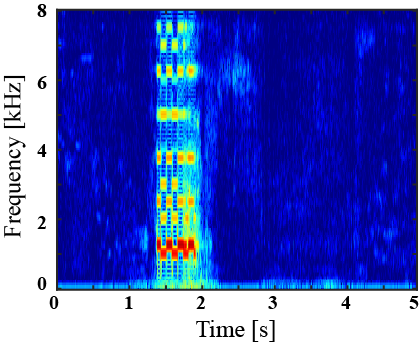
|
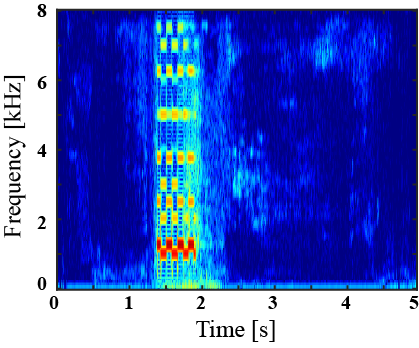
|
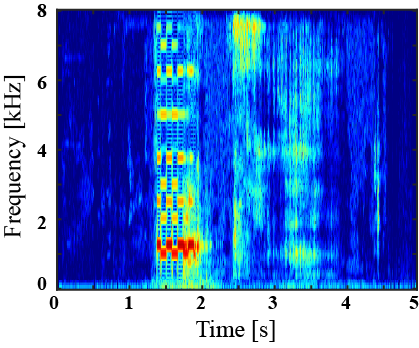
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
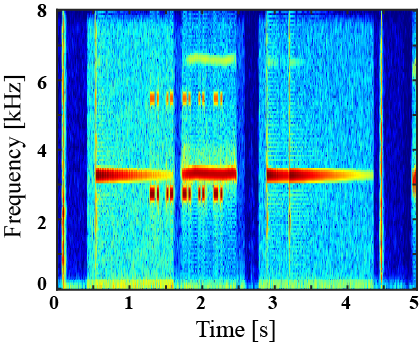
|
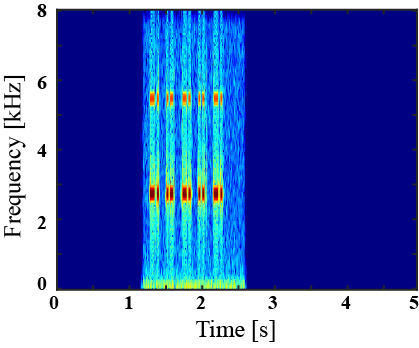
|
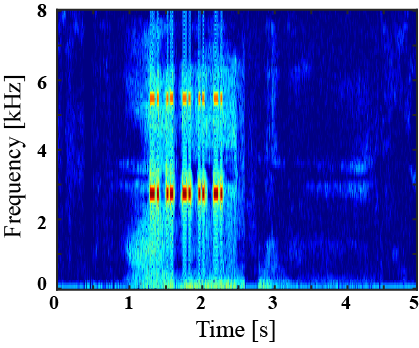
|
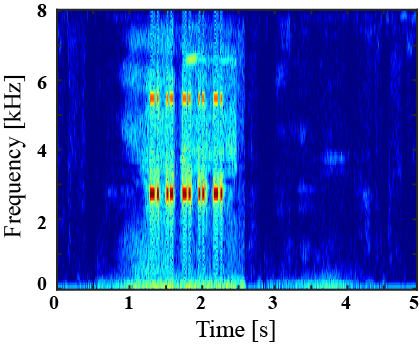
|
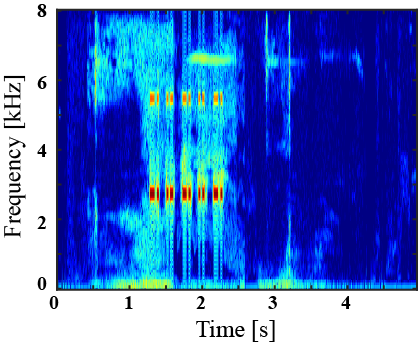
|
(II) Examples of environmental sound extraction using intra-superclass dataset
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|

|
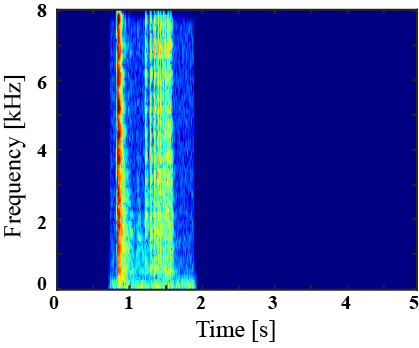
|
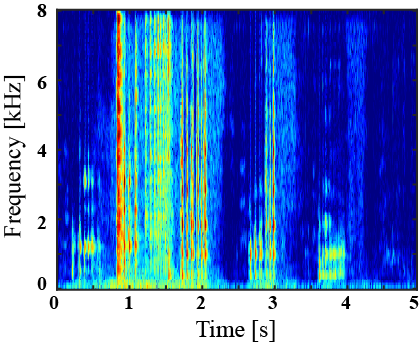
|
|
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
|
|
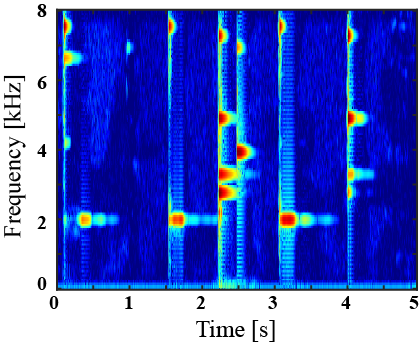
|
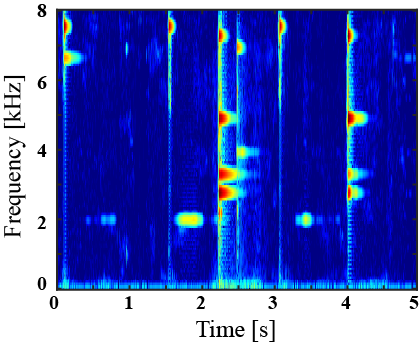
|
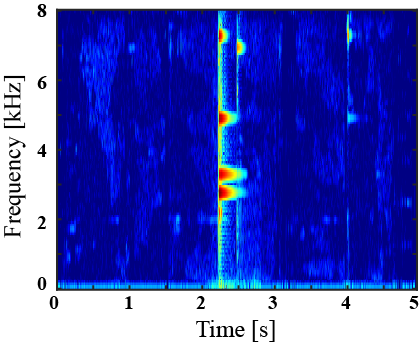
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
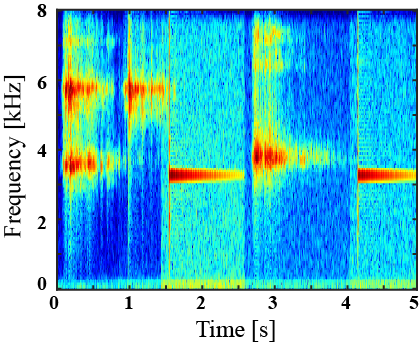
|

|
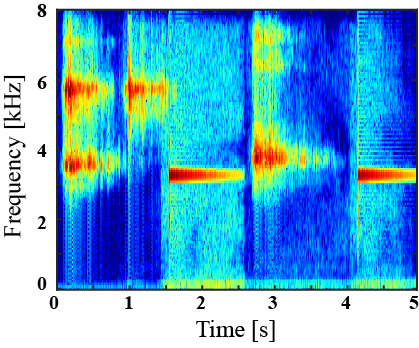
|
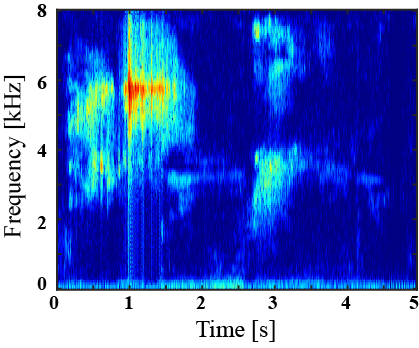
|
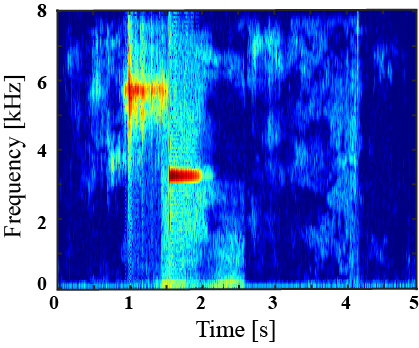
|
(III) Examples of environmental sound extraction using intra-subclass dataset
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
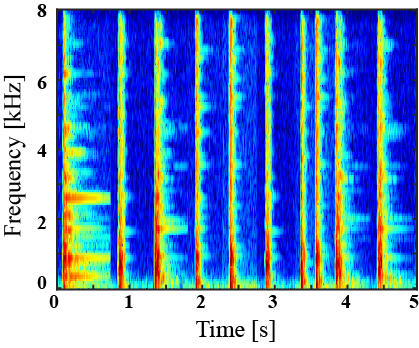
|
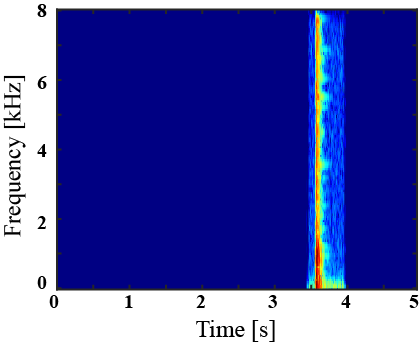
|
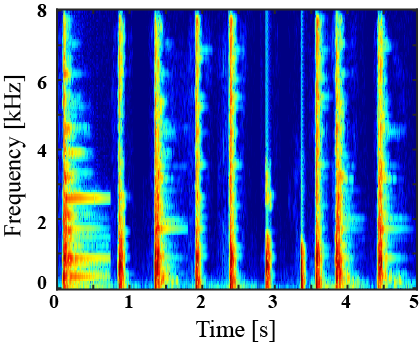
|
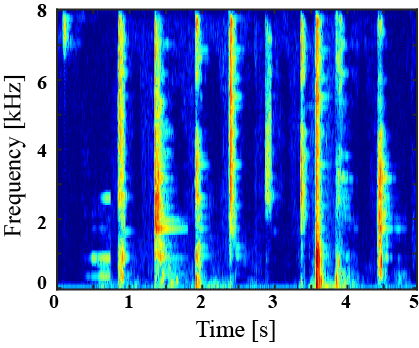
|
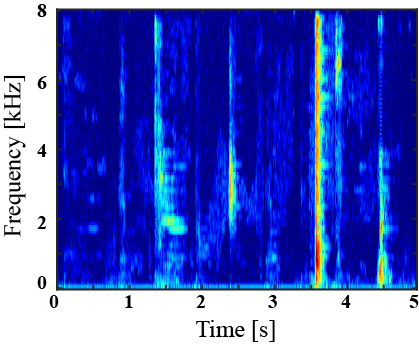
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
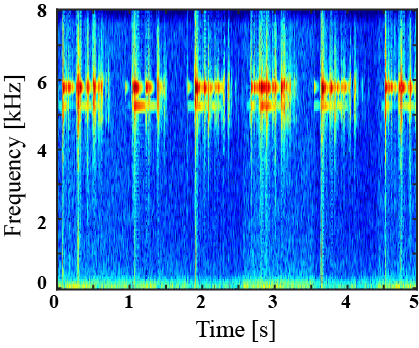
|
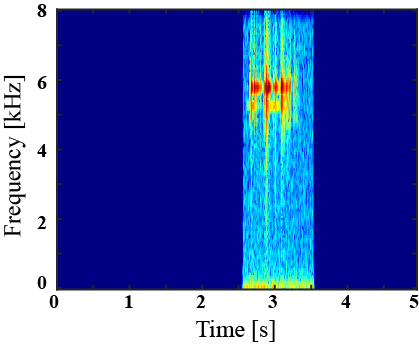
|
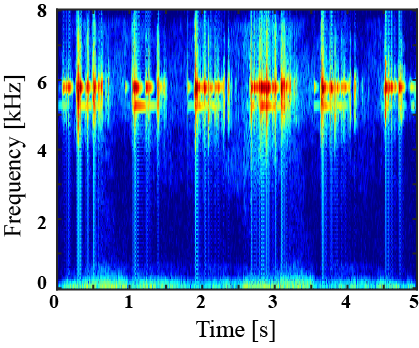
|
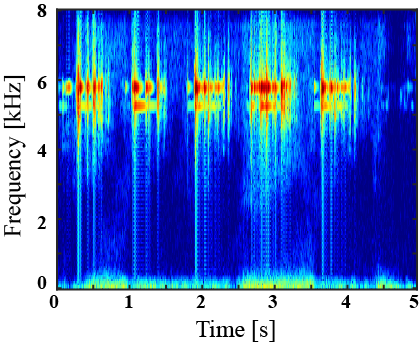
|
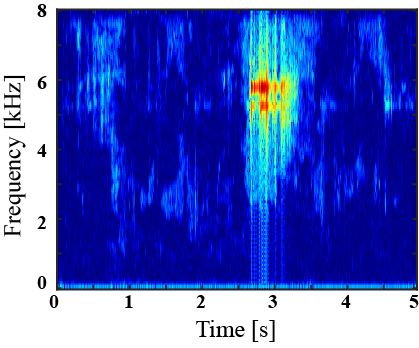
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
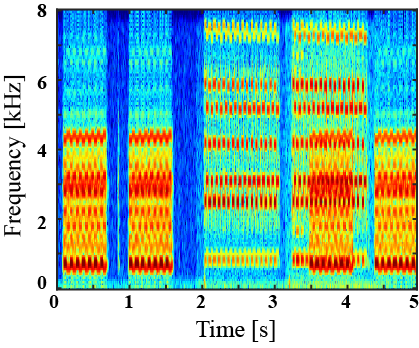
|
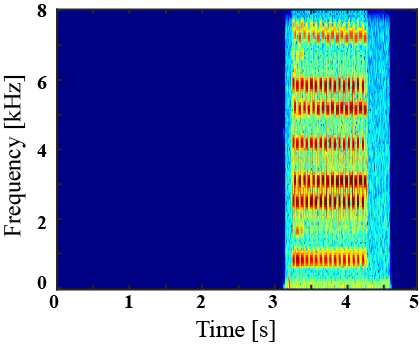
|
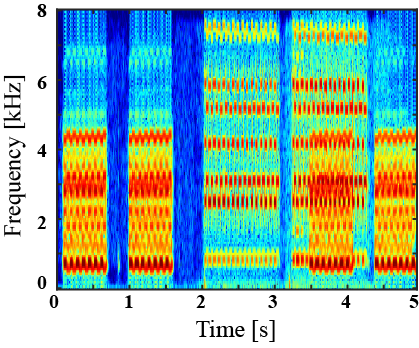
|
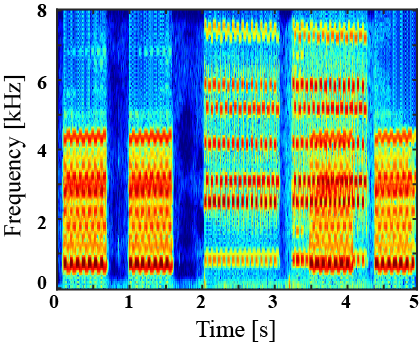
|
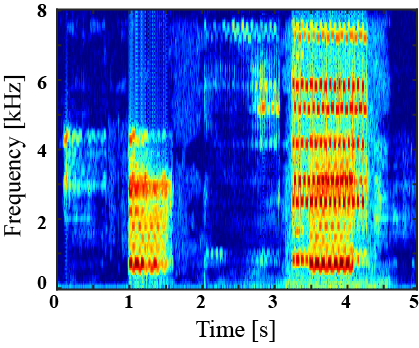
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
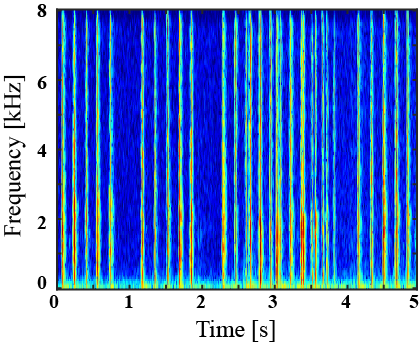
|
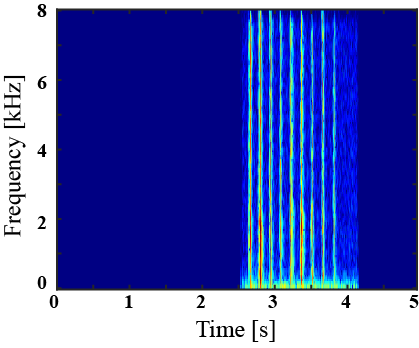
|
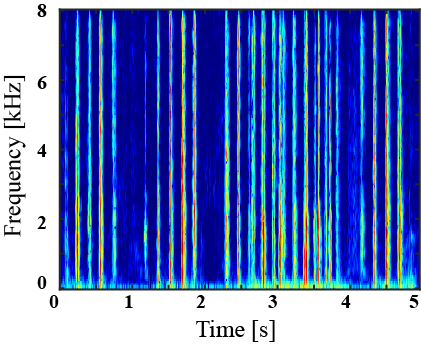
|
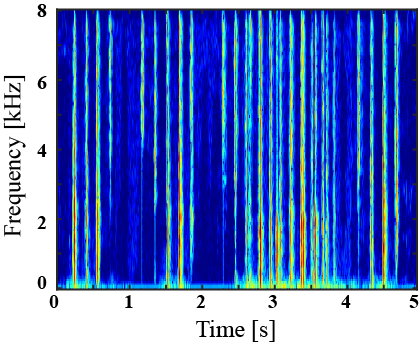
|
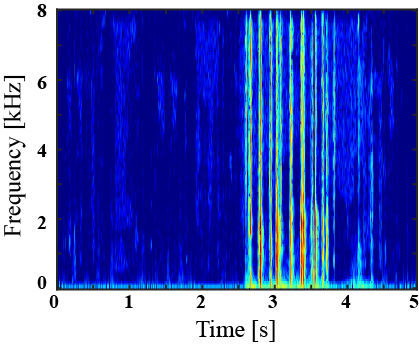
|
| Mixture sound | Ground truth | Superclass-conditioned method (Baseline) |
Subclass-conditioned method (Baseline) |
Onomatopoeia-conditioned method (Proposed) |
|---|---|---|---|---|
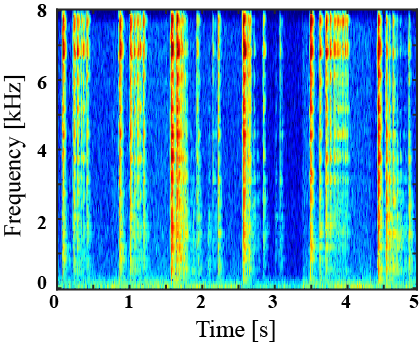
|
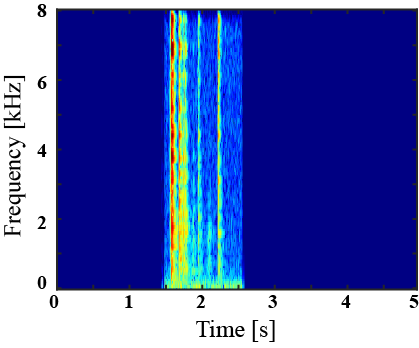
|
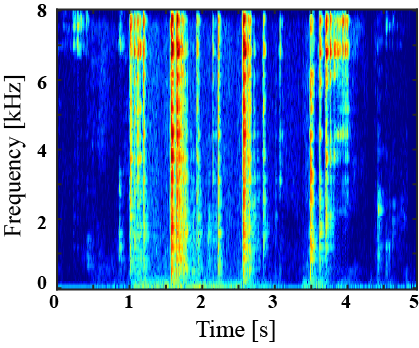
|
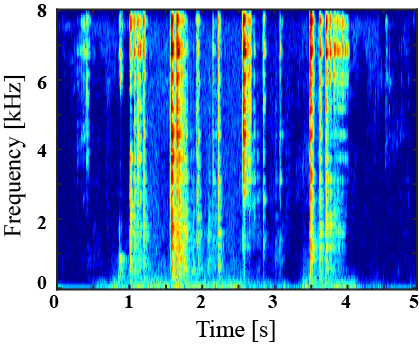
|
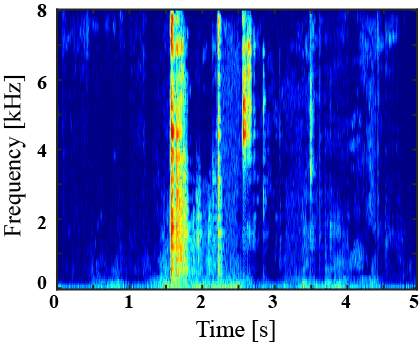
|
[1] S. Nakamura, K. Hiyane, F. Asano, and T. Endo, “Sound scene data collection in real acoustic environments,” The Journal of the Acoustic Society of Japan (E), vol. 20, No. 3, pp. 225–231, 1999.
[2] Yuki Okamoto, Keisuke Imoto, Shinnosuke Takamichi, Ryosuke Yamanishi, Takahiro Fukumori, and Yoichi Yamashita, "RWCP-SSD-Onomatopoeia: Onomatopoeic Word Dataset for Environmental Sound Synthesis," Proc. Detection and Classification of Acoustic Scenes and Events (DCASE), pp. 125-129, 2020.